
NHANES made simple with RNHANES
spend less time munging, and more time analyzing
Scientists spend a lot of time “munging” data. Finding, cleaning, and managing datasets can take up the majority of the time it takes to complete an analysis. Tools that make the munging process easier can save scientists a lot of time.
We are tackling a small part of this problem in the context of the CDC’s National Health and Nutrition Examination Survey, a national study conducted every two years that gathers data on American’s health, nutrition, and exposure to environmental chemicals. Data from NHANES is used widely by environmental health scientists to study the U.S. public’s exposure to chemicals.
Figuring out how to set up a proper analysis of NHANES data can be tricky if you’re starting from scratch. That’s why we wrote RNHANES, an R package that makes it easy to download, analyze, and visualize NHANES data. RNHANES streamlines accessing the data, helps to set up analyses that correctly incorporate the study’s sample weights, and has built in plotting functions.
Let’s take the package for a spin by conducting a real-world analysis of NHANES data. Specifically, let’s characterize the U.S. population’s exposure to PFOA, a perfluo-alkyl substance (PFAS, also called “highly fluorinated compound”) that is linked to a number of adverse health effects.

Installation
A stable version of RNHANES is available in the CRAN package repository, and a development version is available on Github.
# Install stable version
install.packages("RNHANES")
# Install development version
devtools::install_github("silentspringinstitute/RNHANES")Whichever version you install, you need to load the package. We will also be using the tidyverse package in this analysis because it is a handy wrapper package that automatically loads a number of other packages, like ggplot2 and dplyr, for you.
library(tidyverse)
library(RNHANES)Downloading PFAS data
There is a comprehensive index online of the data available through NHANES. The index links to each file and the associated data dictionary. You can use the index to explore the data that is out there.
In our case, we are interested in PFASs. The latest available data on PFASs in NHANES is from the 2011-2012 survey cycle. You can download a data file easily through RNHANES:
pfas_data <- nhanes_load_data("PFC_G", "2011-2012", demographics = TRUE)Summary Statistics
Now that we have the data, we can compute some summary statistics. A good first question to ask is how many people have a detectable level of PFOA in their blood samples, which we can find using the nhanes_detection_frequency function:
nhanes_detection_frequency(pfas_data, "LBXPFOA", "LBDPFOAL")## value cycle begin_year end_year file_name column weights_column
## 1 0.9973545 2011-2012 2011 2012 PFC_G LBXPFOA WTSA2YR
## comment_column name
## 1 LBDPFOAL detection_frequency99.7% of Americans have a detectable level of PFOA in their blood. The logical next step is to find out how much PFOA there is in people’s bodies. The 50th percentile (the median) level gives a estimate of the center of the population, and the 95th percentile an estimate of the levels in highly exposed individuals. With environmental chemicals, there can be large differences in exposure between the 95th and 50th percentiles.
quantiles <- nhanes_quantile(pfas_data, "LBXPFOA", "LBDPFOAL", quantiles = c(0.5, 0.95))Plotting
We can plot the distribution as a histogram of values. This isn’t a very useful way of visualizing the data, because most environmental chemicals are log-normal. That is, the log transformation of the chemical levels roughly follows a normal distribution. We can see this for PFOA by applying a log transformation to the data.
nhanes_hist(pfas_data, "LBXPFOA", "LBDPFOAL")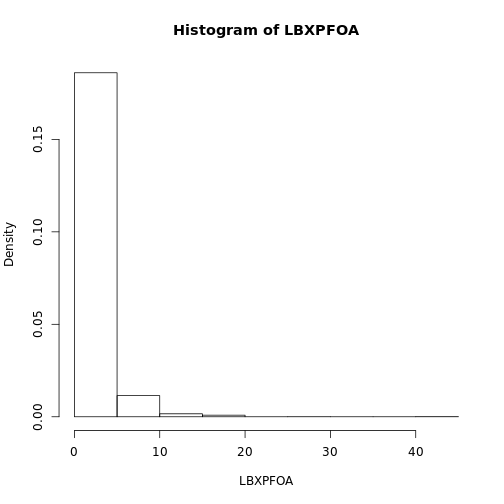
nhanes_hist(pfas_data, "LBXPFOA", "LBDPFOAL", transform="log")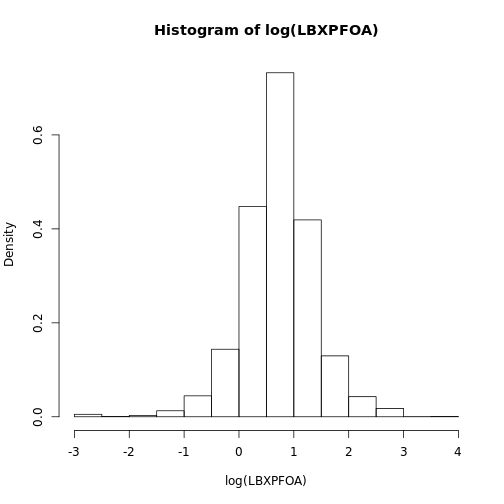
You can learn more about RNHANES on its Github page: http://github.com/silentspringinstitute/RNHANES.